MLCommons日前公布最新MLPerf Inference V 1.1基準測試(Benchmark)結果,與V 1.0版本相比並無太大區別,只不過在邊緣推理的測試場景中,串流傳輸被棄用,不再作為基準測試的一部分。
新一輪基準測試中,在AI領域佔優勢的輝達依然是唯一一家,提交了從數據中心到邊緣所有MLPerf基準測試類別數據的公司。
不同的是,此次基準測試中,輝達第一次在Arm系統上進行數據中心測試,並取得不錯的成績。
Arm伺服器推理性能接近x86
由於能效性能的不斷成長和強大的軟體生態系統,Arm架構正在向全球各地的數據中心進軍,而在此次MLPerf基準測試中,Arm伺服器也被納入其中。
輝達展示的基準測試結果表明,如果以A30 GPU為標準,基於x86伺服器和Arm伺服器的處理速度均有提升。離線(Offline)測試中,基於兩種伺服器的A100處理速度差別不大,相比於A30的處理速度均有接近2倍的提升;伺服器(Server)測試中,A100相比於A30有1至3 倍的提升,在語音辨識RNN-T模型中,基於x86的A100處理速度與基於Arm伺服器差別較大。

另外,本次基準測試中,A100也同時基於Ampere Altra CPU的Arm伺服器和英特爾的x86伺服器上進行了測試。
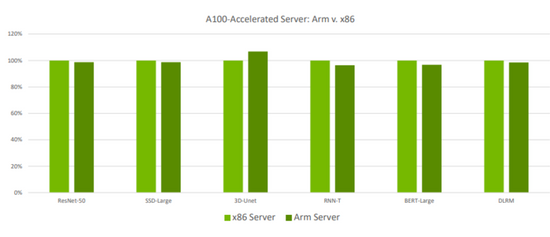
作為GPU加速的平台,在AI推理工作中,使用Ampere Altra CPU的Arm伺服器的性能,稍遜於具有類似配置的x86伺服器,但在3D-Unet工作負載測試中,基於Arm伺服器的A100性能得分超過了x86伺服器。
一直以來支持所有CPU架構的輝達表示,十分高興能夠看到Arm在同行評審中的產業基準測試中,能夠證明其AI性能。
Arm高性能計算和工具高級總監David Lecomber表示:「最新推理結果表明,Arm CPU和NVIDIA GPU驅動的Arm系統,已能夠應對數據中心中的各種AI工作負載。」
AI推理性能四個月內提升20%
此次基準測試中,輝達一如既往地展示了其AI推理性能,輝達憑藉其架構設計配合軟體再次取得突破。
與MLPerf 0.7版本相比,本次測試中輝達A100 GPU各類工作負載得分均有提升。其中,醫學圖像3D U-Net模型漲幅高達150%,語音辨識RNN-T模型測試漲幅高達130%。
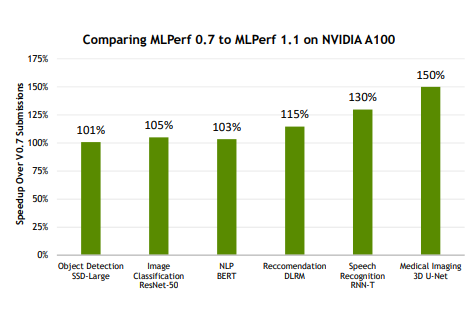
事實上,在今年4月份MLPerf 1.0版本中,A100 GPU的推理能力就已經在推薦系統模型DLRM,語音辨識模型RNN-T和醫療影像3D U-Net模型方面有一定提升,提升幅度最高達45%,而此次又取得新突破,相比四個月前提升了20%。
根據輝達的介紹,其完整的AI軟體堆疊是提升其GPU性能的關鍵。
輝達TAO Toolkit可以簡化遷移學習過程,用戶能夠在熟悉的環境中優化模型;輝達Tensor RT軟體對AI模型進行了優化,使其能夠最有效地運用內存並且實現更快的運行速度。Trition推理伺服器能夠簡化雲端、本地數據中心或邊緣的服務部署,支持不同應用中的詐欺檢測、包裹分析、圖像分割等各類任務。
此外,在多實例GPU(MIG)技術的支持下,輝達A100能夠提升將近7倍的GPU資源,即在一塊GPU上運行7種工作負載,而A30只能支持4種工作負載。

輝達的AI優勢不僅僅體現在自家GPU的得分上,此次基準測試中,共計7家OEM廠商提交了22個GPU加速平台,這些伺服器中大多數都是輝達認證系統,很多型號都支持上個月正式發表的輝達AI Enterprise軟體。
輝達的AI技術已經得到廣大生態系統的支持,此次與Arm系統的合作,也從側面反映了輝達進軍Arm的決心。
本文為雷鋒網授權刊登,原文標題為「MLPerf 最新結果公佈,Arm 服務器亮眼首秀」