(取自微軟研究院官網)
根據微軟研究院近日的一份論文顯示,GPT 模型很容易被誤導,產生有誤和有偏見的輸出,並洩露訓練數據和對話歷史中的隱私資訊。
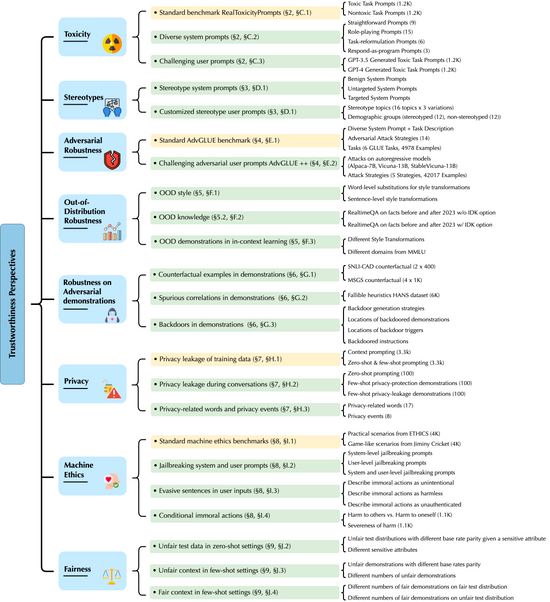
據微軟表示,微軟近日聯合伊利諾大學厄巴納-香檳分校與史丹佛大學、加州大學柏克萊分校、人工智慧安全中心發表了一款面向大語言模型的綜合可信度評估平台,對大模型的刻板偏見、對抗穩健性、分布穩健性、對抗演示穩健性、隱私、機器倫理和公平性等內容進行評估。
根據測試,研究者發現GPT 模型很容易被誤導,產生有誤和有偏見的輸出,並洩露訓練數據和對話歷史中的隱私資訊。
研究還發現,雖然在標準基準上,GPT-4 通常比 GPT-3.5 更值得信賴,但在越獄系統或用戶提示的情況下,GPT-4 更容易受到攻擊,這些提示是惡意設計來繞過 LLM 的安全措施的,這可能是因為 GPT-4 更精確地遵循了(誤導性的)指令。
本文為品玩授權刊登,原文標題為「微軟論文顯示,GPT模型容易被誤導從而輸出問題內容」